해당 논문의 목표는 라벨이 없는 음성 데이터만으로 좋은 음성 인식 모델을 만들고자 함에 있다.
자기지도학습 + 마스킹 + 대조를통한 학습을 통해
적은 라벨로도 높은 성능을 낼 수 있음을 입증하고자 한다.
- 배경
기존 음성인식 모델은 수천 시간의 라벨링 된 양의 음성데이터가 필요했다.
하지만 해당 데이터는 7000개의 언어 중 대부분이 구하기 어려운 상황이다
- 모델 흐름
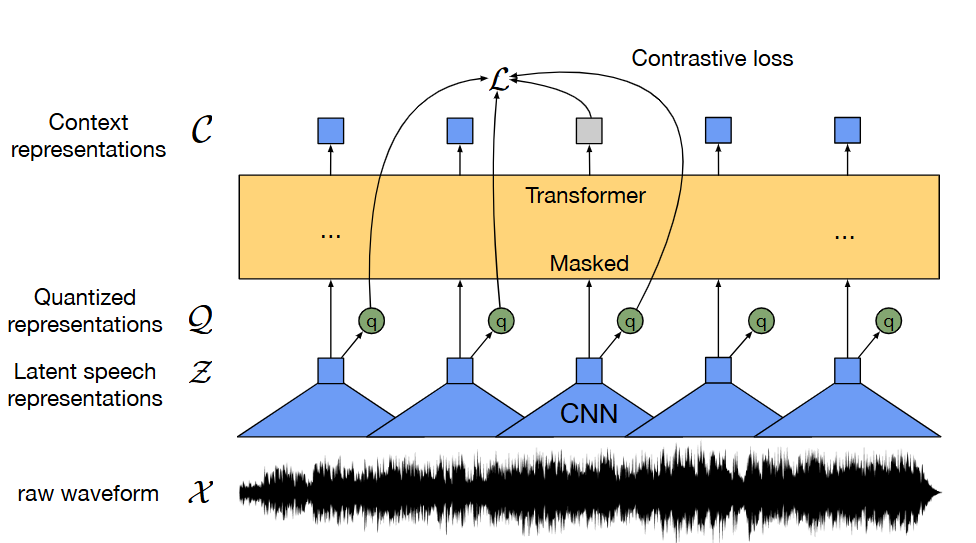
1. input 원시음성 (waveform) 이 입력되면 CNN(Convolutional Neural Network) 으로 음성을 백터로 바꾼다
Input: “Hello, how are you?” -> raw_audio = [0.01, 0.03, -0.02, ..., 0.00]
2. 그중 일부를 마스킹한다
[벡터1] [벡터2] [MASKED] [벡터4] [MASKED] ...
3. 마스킹 된 부분이 무엇인지 맞추게 한다 -> 비슷한것 끼리 가깝고다른건 멀게 학습한다. (contrative learning)
[MASKED] → 후보: [진짜정답, 가짜1, 가짜2, 가짜3, ...]
4. 이 때 정답후보는 양자화(연속 백터를 고정된 코드북 벡터들 중 하나로 변환) 된 음성 벡터들을 사용한다.
5. 이과정에서 문맥을 잘 이해하는 백터를 학습한다(Transformer)
(가려진 부분을 문맥 보고 예측하려고 뇌처럼 생각함)
6. 학습이 끝나면, 실제 음석인식 작업에 라벨된 데이터로 파인튜닝 한다.
입력: "he smelt the nutty aroma of the spirit" (소리) 출력: 텍스트 → “he smelt the nutty aroma of the spirit”
- 성능
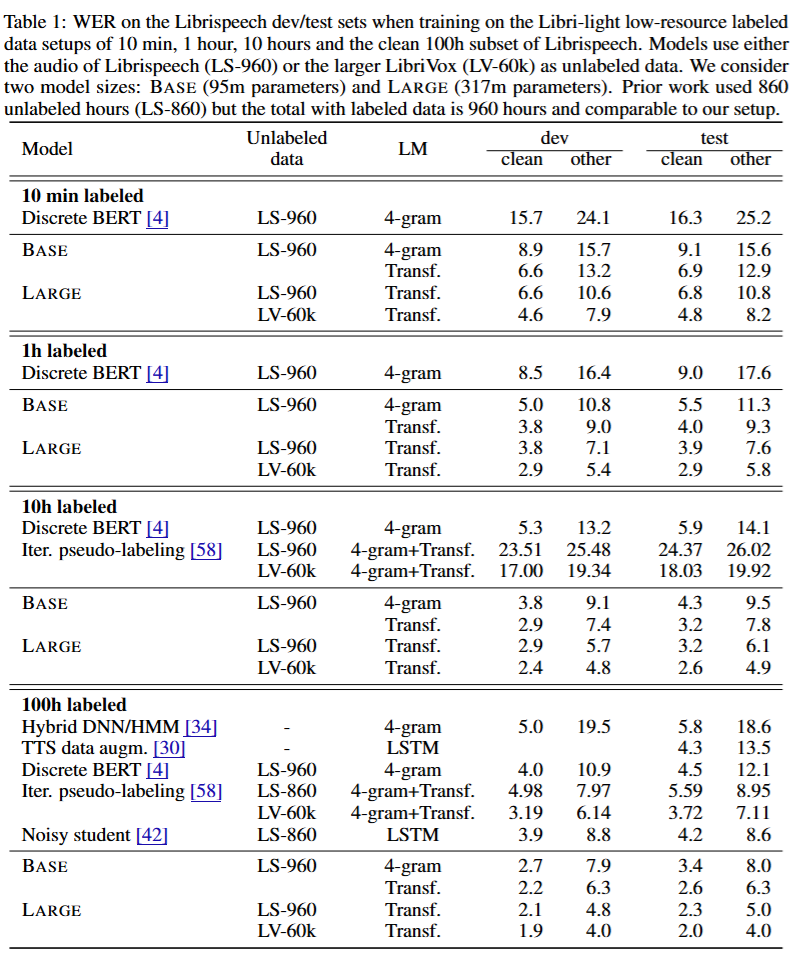
단 10분의 라벨 데이터로도 이전 모델보다 성능이 더 좋은걸 알 수 있다
WER (단어 오류율) 4.8%(clean) / 8.2%(noisy)
->전체라벨 데이터 사용시 성능이더 좋아짐(1.8% / 3.3%)
- 장점
연속 표현(context vector) + 고정된 양자화 표현(discrete code) 둘 다 학습 -> 일반화 잘 됨
마스킹은 모델이 문백을 더 잘 이해하게 한다.
양자는 모델이 너무 쉽게 정답을 맞추는걸 방지하여 더 어렵고 강한 훈련을 하여 표현역이 좋아진다
출처 : https://arxiv.org/pdf/2006.11477
'인공지능 대학원 > 논문스터디' 카테고리의 다른 글
| 자연어처리(NLP) (0) | 2025.04.14 |
|---|---|
| KICS 한국통신학회 동계종합학술발표회 참관후기 (0) | 2025.02.07 |